The small subsets of data were successfully processed using a personal computer but the complete data set must be processed using a computer cluster. Georgia Tech’s PACE computer cluster was selected for the task. A job is submitted in the PACE system using a batch file which designates requested resources, automatic email notifications, and codes to be executed.
Using the PACE computer cluster allows us to do memory-expensive computations by requesting the appropriate node. Nodes with 64GB, 128GB, and 256GB memory capacity are available. In our case where all codes are written in Matlab parallelization is impossible so a single node will be used to carry out computations.
The task of converting raw data to segmented grain boundary data along with the parameter combination is complete and the next step is to gather 2-point statistics for each of these. Before this extensive job was run tests were done on a small subset of five microstructures to determine the appropriate resources for optimal execution time. Some results of these tests are tabulated below.
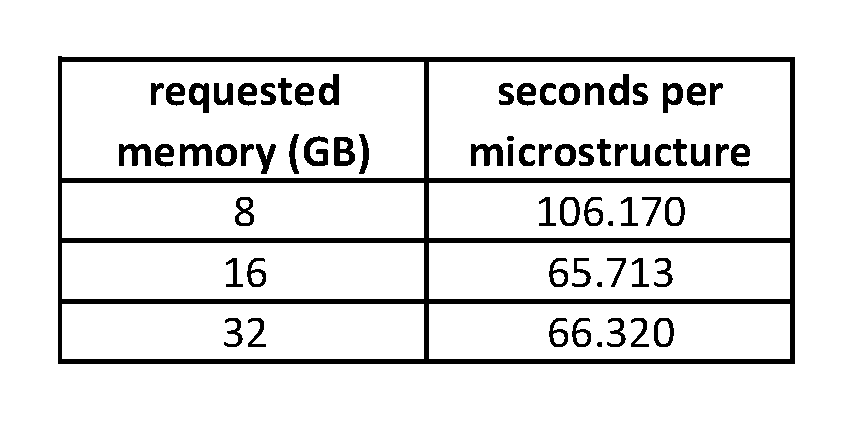 Fig.1. Memory vs. seconds per microstructure on PACE.
Fig.1. Memory vs. seconds per microstructure on PACE.
There is a clear plateu in speed for memory greater than 16GB so 16GB was selected for the job. The estimate of the total duration of the job with 1799 structures is 32.838 hours. The final job was executed in about 42 hours.